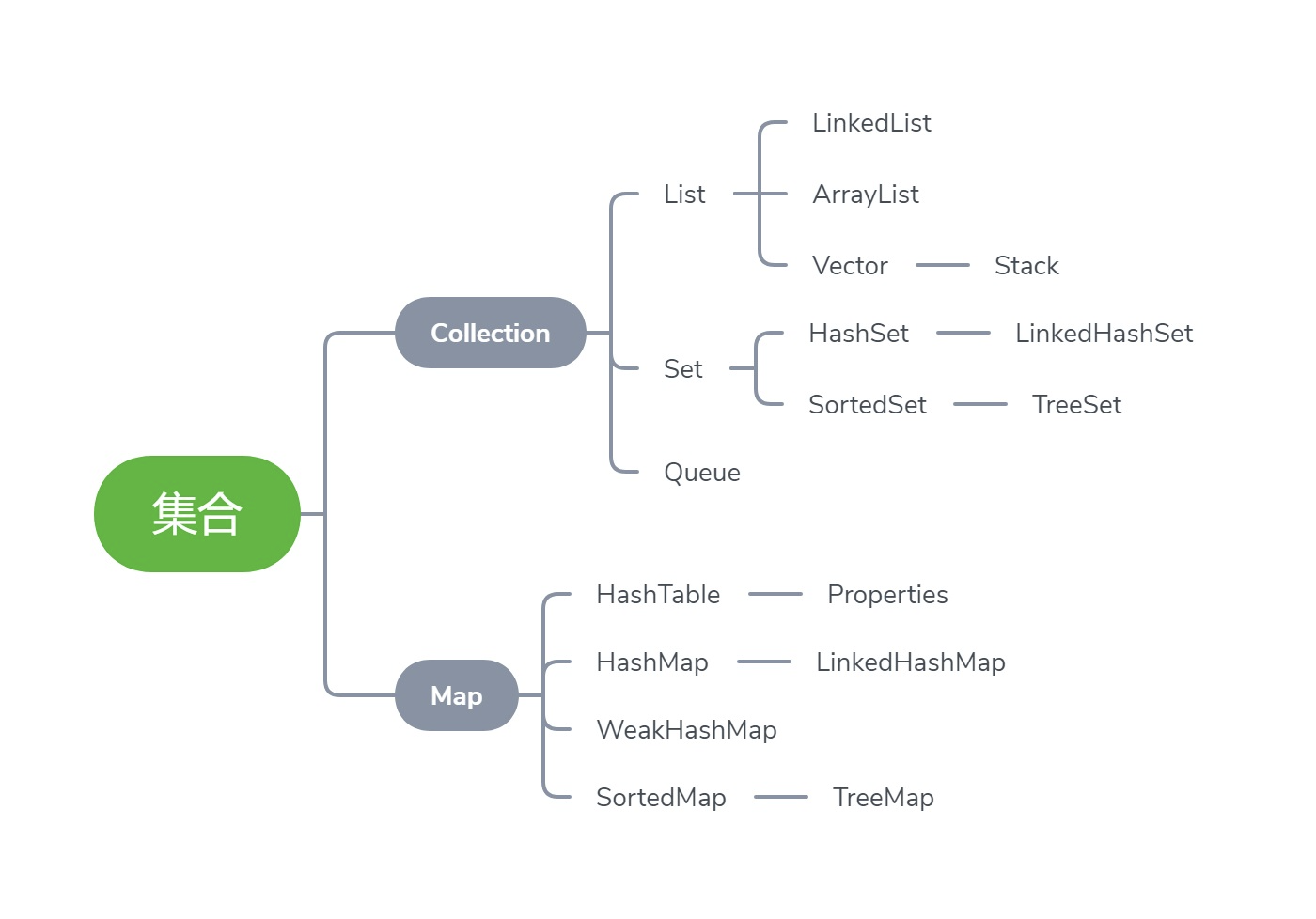
一、List接口
- 特点
- 继承Collection接口,元素时有序的,具有列表的功能,元素顺序均是按照添加的先后顺序进行排列的,不管访问多少次,元素位置不变;
- 允许重复的元素,允许多个null元素;
- 可随机访问包含的元素,可在任意位置上增、删元素;
- 用
Iterator实现单项遍历,也可用Iterator实现双向遍历;注意:用
Iterator进行遍历的时候,不应该调用List、Set、Map等类中的remove()方法删除元素,否则会抛出异常,如果需要在遍历时删除元素,应该使用Iterator.remove()方法;
1、ArrarList
- 1)继承List接口,以数组作为根本的数据结构来实现,元素按顺序存储;
- 2)随机访问很快,但删除头尾元素很慢,新增元素很慢而且费资源;
- 3)适用于无频繁增删数据的情况,比数组效率低;
- 4)非线程安全,可以使用Collections.synchronizedList将其转为线程安全的对象(synchronized),或用安全的List类CopyOnWriteArrayList替代ArrayList;
- 5)初始默认容量为10,加入新元素时会判断是否需要扩容,扩容时内部会通过Array.copy()方法复制数据到新的一个数组中,新的数组的容量根据旧数据容量大小及公式(oldSize+oldSize>>1),即原有大小的的1.5倍,但是:
- 新数组的大小若小于所需要长度时,以所需要长度(与传递参数比较的较大者)作为新的容量;
- 新的大小如果超出最大值(Integer.MAX_VALUE-8)时,以Integer.MAX_VALUE作为新的容量大小;
2、LinkedList
- 1)双向链表结构,以一个静态内部类Node为节点,类中包含三个部分:item、next、prev,可向前或向后遍历,属于链接对象数据结构(类似链表);
- 2)随机访问很慢,但增删操作很快,不耗费多余资源;
- 3)实现了pop()、push()、peek()等操作,可作为栈来使用;
- 4)非线程安全;
3、Vector
- 1)与ArrayList一样继承了相同的父类并实现了相同的接口,底层也都是基于数组实现的,初始默认容量为10;
- 2)多数的public方法添加了synchronized关键字以确保同步,所以Vector是线程安全;
- 3)扩容
- ArrayList有两个属性,储存数据的数组elementData,储存记录数目的size;
- Vector有3个属性,储存记录的数组elementData,储存记录数目的elementCount,扩展数组大小的扩展因子capacityIncrement;
- 扩容方法:ArrayList在满足扩容条件时,扩展后数组大小为原数组长度的1.5倍与传递参数的较大者;Vector在满足扩容条件时,会根据扩容因子来判断,当扩容因子大于0时,新数组长度为原数组长度+扩容因子,否则新数组长度为原数组长度的2倍 ,最后再将长度与传递参数对比,较大者为新数组最终的长度;
4、Stack
- 1)继承Vector,基于动态数组实现的LIFO数据结构,可被当作堆栈来使用;
- 2)线程安全;
二、Set
- 特点
- 不允许重复元素,有且最多只有一个null元素,通过equals()来判断是否重复;
- 不可随机访问被包含的元素;
- 只能使用Iterator实现单向遍历
1、HashSet
- 1)使用HashMap作为底层数据结构来实现Set;
- 2)元素时无序的,迭代遍历方向的顺序与加入的顺序不同,多次迭代得到的元素顺序可能不同;
- 3)加入元素时,会通过元素的hashCode()方法来得到元素的hashCode值,并根据hashCode值来确定该元素在集合中的储存位置,当两个元素hashCode不相同时会存储在不同位置上,若储存元素对应位置上存在元素,则通过equals()进行对比
- equals()返回true时,即判断为同一元素并拒绝加入集合;
- equals()返回false时,也可以加加入集合,但此时情况有所不同,因试图将两个元素存在同个位置上失败,所以该位置上的数据会转而使用链式结构来储存多个元素,进而导致通过hashCode快速定位访问元素的性能下降;
- 4)因为基于HashMap实现,所以其容量初始大小也为16,扩容因子为0.75;
- 5)非线程安全;
2、LinkedHashSet
- 1)继承HashSet,但底层基于LinkedHashMap来实现,其操作与HashSet基本一致;
- 2)LinkedHashSet是Ordered,基于双链表实现,迭代访问元素的顺序与加入的顺序相同,多次迭代遍历元素的顺序不变,可以说是一种有序的数据结构;
- 3)整体性能比HashSet差,但迭代访问全部元素时,性能更好;
- 4)非线程安全;
3、SortedSet
- 1)保证迭代器按照元素递增顺序遍历的集合,可以按照元素的自然顺序进行排序;
- 2)加入的元素必须实现Comparable接口;
- 3 )元素是有序的;
4、TreeSet
- 1)基于TreeMap实现的SortedSet,所以元素的储存与HashSet不同,HashSet根据元素的HashCode值来确定位置,而TreeSet与TreeMap一样,以红黑树作为数据结构来存储元素;
- 2)默认自然排序为升序,但可以通过指定Comparator来实现自定义排序;
- 3)非线程安全;
- 4)判断两个元素不相等的方式是通过equals()返回false,或compareTo()方法比较返回非0结果;
三、Map
- 特点
- 映射集,键值对集合,键和值一一对应;
- 不允许重复的键,但值可以重复;
1、Hashtable
- 1)继承了Dictionary并实现了Map接口;(Dictionary是声明了操作”键值对”函数接口的抽象类)
- 2)作为键的对象必须实现了hashCode()、equals()方法,所以只能是Object及其子类,基本数据类型不可以,除非使用其包装类对象;
- 3)键和值都不能为空;
- 4)以数组+单链表的形式储存数据结构,多次访问,元素映射的顺序不保证一致;
- 5)通过synchronized方法实现线程安全;
- 6)已弃用,不建议使用;
2、Properites
- 1)键和值都是字符串;
3、HashMap
- 1)键和值都可以是null,但键有且最多只有一个为null;
- 2)不保证映射的顺序,多次访问、映射的元素顺序可能不同;
- 3)数组+链表/红黑树作为数据结构;
- 4)非线程安全,可以使用Collections.synchronizedMap将其转为线程安全的对象(效率不高),或用安全的数据类型ConcurrentHashMap;
- 5)时间复杂度:HashMap通过数组和链表实现,数组查找的时间复杂度是O(1),链表的时间复杂度是O(n),所以要让HashMap尽可能的块,就需要链表的长度尽可能的小,当链表长度是1是,HashMap的时间复杂度就变成了O(1);根据HashMap的实现原理,要想让链表长度尽可能的短,需要hash算法尽量减少冲突
;链表的查找复杂度是O(n),红黑树是O(log(n)) - 6)扩容原理:默认情况下,HahMap的初始容量大小为16,负载因子loadFactor为0.75,当数组中元素个数达到数组大小loadFactor后会自动扩大数组大小,也就是当HashMap中元素个数达到(160.75),即12时,会自动创建容量大小为(2*当前容量)的新数组,并复制数据到新数组中,并重新计算元素在新数组中的位置;
- 7)hash冲突:与HashSet类似,以key的hashCode来决定元素在集合中的位置,但当元素储存位置重复,即hashCode值一致,而equals()对比返回false时,该位置上的多个元素将转为使用链表的形式进行储存,需要注意的是,在Java8中,当该位置上储存元素的链表长度大于8时,将转为使用红黑树来储存数据;
4、LinkedHashMap
- 1)继承HashMap,双向链表数据结构;
- 2)以插入顺序排序,多次访问,元素映射顺序一致;
- 3)性能并HashMap差,但迭代遍历全部元素时有较好的性能;
5、WeakHashMap
- )继承抽象AbstractMap类,但与HashMap用法基本相似,HashMap的key保留了对实际对象的强引用,只要HashMap没有销毁,HashMap中所有Key所引用的对象就不会被垃圾回收,HashMap也不会自动删除这些key所所对应的键值对;但WeakHashMap的key只保留的对实际对象的弱引用,意味着如果WeakHashMap中key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能会被垃圾回收,WeakHashMap也可能自动删除这些key对应的键值对;
6、SortedMap
- 1)保证按照键的升序排列的映射;
- 2)所有键必须实现Comparable接口;
- 3)作为SortedSet的底层数据结构;
7、TreeMap
- 1)基于红黑树的SortedMap接口实现类;
- 2)非线程安全;
- 3)作为TreeSet的底层数据结构;
四、安全类
1、ConcurrentHashMap
- 替代HashMap的线程安全实现类
- 以分段锁实现线程安全
- 具体实现根据jdk版本而定
2、CopyOnWriteArrayList
- 替代ArrayList的线程安全实现类
五、其他
1、SparseArray
- 键值对集合
- 初始大小为10
数据存储
通过两个数组分开存放key、value
1
2private int[] mKeys;
private Object[] mValues;key必须是int类型,但避免了自动装箱转换成Integer
- 二分法定位、查找数据,一般情况下具有较好的性能,但大数据集合下性能降低
2、Collections实现同步
- 原理(以synchronizedMap为例)
- 创建并返回一个SynchronizedMap,即HashMap的包装类
- SynchronizedMap中各个函数通过synchronized代码块实现线程安全;
- Collections中的其他同步方法实现原理基本一致;
- 但SynchronizedMap效率比安全类ConcurrentHashMap差,因为ConcurrentHashMap内部是分段锁形式实现的,最小单位是桶,每个桶之间的线程安全互不干扰;